I am a beginner in dicom.I compiled DCMTK using CMake GUI on Windows. The CMake version is 3.26.5. During compilation, I selected WITH_LIBICONVINC, and there were no errors reported. After compiling, I executed the findscu.exe with the query command: findscu.exe -v -aet asdasd -aec DICOM -d 192.168.45.137 11122 -k "PatientName=*" -k "PatientBirthDate=*" -k "SpecificCharacterSet=ISO_IR 192". However, the Chinese patient names retrieved from the query result were garbled. I also utilized the DCMTK library in a C++ console application for querying, but the patient names retrieved were also garbled. I've been researching this issue for about two days, and I've checked forum posts since 2017, but I haven't found a solution. I believe there is no issue with my DICOM server because my colleague successfully retrieved the correct Chinese patient name using a DICOM library on Android.Below is the output from my findscu:
E:\workspace\Dicom\building3.6.7\build\bin\Debug>findscu.exe -v -aet asdasd -aec DICOM -d 192.168.45.137 11122 -k "PatientName=*" -k "PatientBirthDate=*" -k "SpecificCharacterSet=ISO_IR 192" +dc
D: $dcmtk: findscu v3.6.7 2022-04-22 $
D:
D: Request Parameters:
D: ====================== BEGIN A-ASSOCIATE-RQ =====================
D: Our Implementation Class UID: 1.2.276.0.7230010.3.0.3.6.7
D: Our Implementation Version Name: OFFIS_DCMTK_367
D: Their Implementation Class UID:
D: Their Implementation Version Name:
D: Application Context Name: 1.2.840.10008.3.1.1.1
D: Calling Application Name: asdasd
D: Called Application Name: DICOM
D: Responding Application Name: DICOM
D: Our Max PDU Receive Size: 16384
D: Their Max PDU Receive Size: 0
D: Presentation Contexts:
D: Context ID: 1 (Proposed)
D: Abstract Syntax: =FINDModalityWorklistInformationModel
D: Proposed SCP/SCU Role: Default
D: Proposed Transfer Syntax(es):
D: =LittleEndianExplicit
D: =BigEndianExplicit
D: =LittleEndianImplicit
D: Requested Extended Negotiation: none
D: Accepted Extended Negotiation: none
D: Requested User Identity Negotiation: none
D: User Identity Negotiation Response: none
D: ======================= END A-ASSOCIATE-RQ ======================
I: Requesting Association
D: setting network send timeout to 60 seconds
D: setting network receive timeout to 60 seconds
D: Constructing Associate RQ PDU
D: PDU Type: Associate Accept, PDU Length: 187 + 6 bytes PDU header
D: 02 00 00 00 00 bb 00 01 00 00 44 49 43 4f 4d 20
D: 20 20 20 20 20 20 20 20 20 20 61 73 64 61 73 64
D: 20 20 20 20 20 20 20 20 20 20 00 00 00 00 00 00
D: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
D: 00 00 00 00 00 00 00 00 00 00 10 00 00 15 31 2e
D: 32 2e 38 34 30 2e 31 30 30 30 38 2e 33 2e 31 2e
D: 31 2e 31 21 00 00 1b 01 00 00 00 40 00 00 13 31
D: 2e 32 2e 38 34 30 2e 31 30 30 30 38 2e 31 2e 32
D: 2e 31 50 00 00 3b 51 00 00 04 00 00 ff ff 52 00
D: 00 22 31 2e 32 2e 33 30 30 2e 35 35 36 34 37 31
D: 37 33 2e 37 32 33 38 30 31 30 2e 35 2e 30 2e 33
D: 2e 35 2e 34 55 00 00 09 53 41 4e 54 45 53 4f 46
D: 54
D: Parsing an A-ASSOCIATE PDU
W: ASSOC: PDV send length 65535 is odd (using 65534)
D: Association Parameters Negotiated:
D: ====================== BEGIN A-ASSOCIATE-AC =====================
D: Our Implementation Class UID: 1.2.276.0.7230010.3.0.3.6.7
D: Our Implementation Version Name: OFFIS_DCMTK_367
D: Their Implementation Class UID: 1.2.300.55647173.7238010.5.0.3.5.4
D: Their Implementation Version Name: SANTESOFT
D: Application Context Name: 1.2.840.10008.3.1.1.1
D: Calling Application Name: asdasd
D: Called Application Name: DICOM
D: Responding Application Name: DICOM
D: Our Max PDU Receive Size: 16384
D: Their Max PDU Receive Size: 65535
D: Presentation Contexts:
D: Context ID: 1 (Accepted)
D: Abstract Syntax: =FINDModalityWorklistInformationModel
D: Proposed SCP/SCU Role: Default
D: Accepted SCP/SCU Role: Default
D: Accepted Transfer Syntax: =LittleEndianExplicit
D: Requested Extended Negotiation: none
D: Accepted Extended Negotiation: none
D: Requested User Identity Negotiation: none
D: User Identity Negotiation Response: none
D: ======================= END A-ASSOCIATE-AC ======================
I: Association Accepted (Max Send PDV: 65522)
I: Sending Find Request
D: ===================== OUTGOING DIMSE MESSAGE ====================
D: Message Type : C-FIND RQ
D: Presentation Context ID : 1
D: Message ID : 1
D: Affected SOP Class UID : FINDModalityWorklistInformationModel
D: Data Set : present
D: Priority : medium
D: ======================= END DIMSE MESSAGE =======================
I: Request Identifiers:
I:
I: # Dicom-Data-Set
I: # Used TransferSyntax: Little Endian Explicit
I: (0008,0005) CS [ISO_IR 192] # 10, 1 SpecificCharacterSet
I: (0010,0010) PN [*] # 2, 1 PatientName
I: (0010,0030) DA [*] # 2, 1 PatientBirthDate
I:
D: DcmDataset::read() TransferSyntax="Little Endian Implicit"
D: DcmDataset::read() TransferSyntax="Little Endian Explicit"
I: Received Find Response 1
D: ===================== INCOMING DIMSE MESSAGE ====================
D: Message Type : C-FIND RSP
D: Message ID Being Responded To : 1
D: Affected SOP Class UID : FINDModalityWorklistInformationModel
D: Data Set : present
D: DIMSE Status : 0xff00: Pending: Matches are continuing
D: ======================= END DIMSE MESSAGE =======================
D: Response Identifiers:
D:
D: # Dicom-Data-Set
D: # Used TransferSyntax: Little Endian Explicit
D: (0008,0005) CS [ISO_IR 192] # 10, 1 SpecificCharacterSet
D: (0010,0010) PN [worklis闃縘 # 10, 1 PatientName
D: (0010,0030) DA [19990202] # 8, 1 PatientBirthDate
D:
D: DcmDataset::read() TransferSyntax="Little Endian Implicit"
D: DcmDataset::read() TransferSyntax="Little Endian Explicit"
FindSCU Chinese Unicode problem
Moderator: Moderator Team
-
J. Riesmeier
- DCMTK Developer
- Posts: 2506
- Joined: Tue, 2011-05-03, 14:38
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
Specifying the Specific Character Set (0008,0005) in your query is not needed since your query does not contain any non-ASCII characters.
In order to make sure that it is not a display problem on your side (Windows command shell or terminal?), you should write the received C-FIND Response Data Sets to file, e.g. using findscu's --extract option.
In order to make sure that it is not a display problem on your side (Windows command shell or terminal?), you should write the received C-FIND Response Data Sets to file, e.g. using findscu's --extract option.
Re: FindSCU Chinese Unicode problem
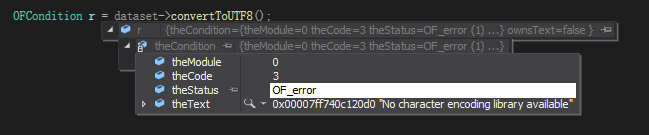
I added the -- extract xml parameter, which can display Chinese correctly in the exported XML file. However, I hope to obtain the patient's Chinese name through encoding. I called dataset ->convertToUTF8(), but the call failed with the error message 'No Character encoding library available'.The patient's Chinese name obtained through FindSCUCallback:: callback is garbled code
-
Marco Eichelberg
- OFFIS DICOM Team

- Posts: 1445
- Joined: Tue, 2004-11-02, 17:22
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
If you want DCMTK to convert character sets, then you need to compile it with one of the character set conversion libraries supported, i.e. GNU libiconv or ICU.
Re: FindSCU Chinese Unicode problem
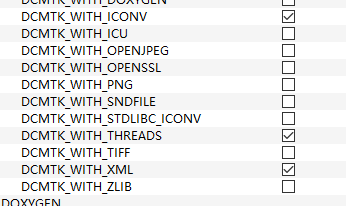
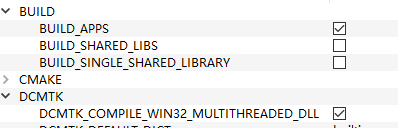
Yes, I chose WITH_LIBICONVINC when compiling DCMTK using CMake.But still unable to correctly convert character encoding. The obtained patient's Chinese name is garbled code.I don't know where the problem is.Here are my compiling options, and I have sent a few pictures

https://img2023.cnblogs.com/blog/224245 ... 023981.png

https://img2023.cnblogs.com/blog/224245 ... 148341.png

https://img2023.cnblogs.com/blog/224245 ... 648542.jpg

https://img2023.cnblogs.com/blog/224245 ... 272111.jpg
https://img2023.cnblogs.com/blog/224245 ... 023981.png
{kind=link}
https://img2023.cnblogs.com/blog/224245 ... 148341.png
{kind=link}
https://img2023.cnblogs.com/blog/224245 ... 648542.jpg
{kind=link}
https://img2023.cnblogs.com/blog/224245 ... 272111.jpg
{kind=link}
-
J. Riesmeier
- DCMTK Developer
- Posts: 2506
- Joined: Tue, 2011-05-03, 14:38
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
What is the value of the CMake option "DCMTK_ENABLE_CHARSET_CONVERSION"?
PS: Your referenced images are currently not shown.
PS: Your referenced images are currently not shown.
Re: FindSCU Chinese Unicode problem
Thank you. After selecting "DCMTK-ENABLE-CHARSET-CONVERSION" and then calling dataset ->convertCharacterSet ("ISO-IR 192", "GB18030"), I can display Chinese correctly. I have two more questions
1. Why ISO_ IR 192 cannot display Chinese correctly
2. How should I search for Chinese patient names? The following is the method I am currently using, but it does not work
OFList<OFString> overrideKeys;
overrideKeys.push_back("PatientName=张三");
1. Why ISO_ IR 192 cannot display Chinese correctly
2. How should I search for Chinese patient names? The following is the method I am currently using, but it does not work
OFList<OFString> overrideKeys;
overrideKeys.push_back("PatientName=张三");
-
J. Riesmeier
- DCMTK Developer
- Posts: 2506
- Joined: Tue, 2011-05-03, 14:38
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
This call should return an error, since "ISO-IR 192" is no Defined Term in DICOM (in contrast to "ISO_IR 192") and conversion to "GB18030" is not yet implemented in the DCMTK (in contrast to conversion from this character set).dataset ->convertCharacterSet ("ISO-IR 192", "GB18030")
What do you mean by that? Display by which application?1. Why ISO_ IR 192 cannot display Chinese correctly
If you use non-ASCII characters in your Query, you need to provide the character set that is used for the encoding of these characters in the Specific Character Set (0008,0005) Attribute. E.g.:How should I search for Chinese patient names?
Code: Select all
SpecificCharacterSet="ISO_IR 192"
PatientName="张三"Re: FindSCU Chinese Unicode problem
Sorry, ISO-IR 192 is a spelling error in my post. In my code, I actually wrote dataset ->convertCharacterSet ("ISO_IR 192", "GB18030")
I cannot obtain correct patient information by specifying (00080005) as either ISO_IR 192 or GB18030
I have modified the DCMTK source code by adding dset ->convertCharacterSet ("GB18030", "ISO_IR 192") in DcmFindSCU:: findSCU();, Now it's working properly. But I don't think it's the right solution
I cannot obtain correct patient information by specifying (00080005) as either ISO_IR 192 or GB18030
I have modified the DCMTK source code by adding dset ->convertCharacterSet ("GB18030", "ISO_IR 192") in DcmFindSCU:: findSCU();, Now it's working properly. But I don't think it's the right solution
-
J. Riesmeier
- DCMTK Developer
- Posts: 2506
- Joined: Tue, 2011-05-03, 14:38
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
The Specific Character Set (0008,0005) Attribute in your Query just specifies the character encoding of your query. The SCP is free to send C-FIND response datasets with a different character encoding, which is specified by the Specific Character Set (0008,0005) Attribute of the response dataset.I cannot obtain correct patient information by specifying (00080005) as either ISO_IR 192 or GB18030
If a C-FIND response dataset is encoded with "GB18030" and you want to obtain "UTF-8", then of course you need to convert the dataset prior to use it for display purposes (or the like).I have modified the DCMTK source code by adding dset ->convertCharacterSet ("GB18030", "ISO_IR 192") in DcmFindSCU:: findSCU();, Now it's working properly. But I don't think it's the right solution
I am sorry, but you should provide more background information and details on your use case if you want someone else to help you in this regard.
Re: FindSCU Chinese Unicode problem
Now I can correctly display the C-FIND response dataset containing Chinese content. My problem is that I cannot set the query criteria for Chinese
For example, there is a patient data named "张三" in my worklist, and I am currently unable to find any data through the following two methods, which means that I got 0 data
My current approach is to modify the DCMTK source code. I added dset ->convertCharacterSet ("GB18030", "ISO_IR 192") in the DcmFindSCU:: findSCU() function in dcmnet/libsrc/dfindscu.cc, which is approximately the 700th line of dfindscu.cc. Now the source code has changed to
After modifying the source code, I can obtain patient data by specifying the query condition as PatientName="张三"
For example, there is a patient data named "张三" in my worklist, and I am currently unable to find any data through the following two methods, which means that I got 0 data
Code: Select all
SpecificCharacterSet="ISO_IR 192"
PatientName="张三"
Code: Select all
SpecificCharacterSet="GB18030"
PatientName="张三"
Code: Select all
while (path != endOfList)
{
cond = proc.applyPathWithValue(dset, *path);
if (cond.bad())
{
DCMNET_ERROR("Bad override key/path: " << *path << ": " << cond.text());
return cond;
}
path++;
}
dset->convertCharacterSet("GB18030", "ISO_IR 192");-
J. Riesmeier
- DCMTK Developer
- Posts: 2506
- Joined: Tue, 2011-05-03, 14:38
- Location: Oldenburg, Germany
- Contact:
Re: FindSCU Chinese Unicode problem
If the name of the patient you want to query is encoded in GB 18030, you need to specify this character set (i.e. "GB18030") in the Specific Character Set (0008,0005) Attribute. If the name is encoded in UTF-8, you need to specify "ISO_IR 192".
However, if the SCP does not support matching names in GB 18030 encoding, then of course it makes sense to convert your query to UTF-8 (as you apparently did in your current approach [*]) and specify this in the Specific Character Set (0008,0005).
As I already wrote, details on what the SCP supports should be available from the DICOM Conformance Statement.
[*] There is no need to modify the DCMTK for this purpose. You should just provide the UTF-8 encoding of the name to the corresponding DCMTK method.
By the way, the first name component of a Patient's Name (VR=PN) should always be the alphabetic representation of the name, i.e. instead of "张三" this could be "Doe^John". So, the full name would be "Doe^John=张三" or "Doe^John=三^张" (not sure about the latter).
Also your sample name does not seem to consist of last and first name, but only of a last name (since the "^" delimiter is missing). A valid example of a Chinese person name can be found in DICOM PS3.5 Section J3.
However, if the SCP does not support matching names in GB 18030 encoding, then of course it makes sense to convert your query to UTF-8 (as you apparently did in your current approach [*]) and specify this in the Specific Character Set (0008,0005).
As I already wrote, details on what the SCP supports should be available from the DICOM Conformance Statement.
[*] There is no need to modify the DCMTK for this purpose. You should just provide the UTF-8 encoding of the name to the corresponding DCMTK method.
By the way, the first name component of a Patient's Name (VR=PN) should always be the alphabetic representation of the name, i.e. instead of "张三" this could be "Doe^John". So, the full name would be "Doe^John=张三" or "Doe^John=三^张" (not sure about the latter).
Also your sample name does not seem to consist of last and first name, but only of a last name (since the "^" delimiter is missing). A valid example of a Chinese person name can be found in DICOM PS3.5 Section J3.
Re: FindSCU Chinese Unicode problem
Thank you, my problem has been resolved. I don't need to modify the DCMTK source code now. I will perform encoding conversion before passing in the query conditions, and the code is as follows
Code: Select all
OFCharacterEncoding encoding;
encoding.selectEncoding("","UTF-8");
OFString patientName;
encoding.convertString("PatientName=张三",patientName);
overrideKeys.push_back(patientName);
overrideKeys.push_back("SpecificCharacterSet=ISO_IR 192");
OFCondition cond = findscu.performQuery(...);
Who is online
Users browsing this forum: Ahrefs [Bot], Bing [Bot], Google [Bot] and 1 guest